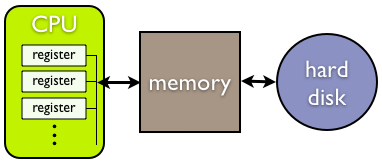
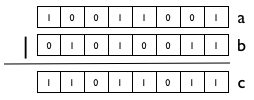
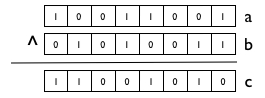
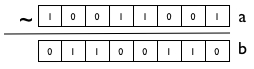
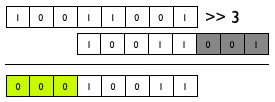
11. define과 디버깅
11.1 define
define은 컴파일 직전에 특정 문자를 지정한 문자로 대체해 주는 전처리기 입니다. C의 전처리기에 대해서는 이전 포스트에서 살펴 보았습니다. define은 아래와 같이 선언하고 사용합니다.
#define [dest] [src]
define은 [src]를 소스내에서 [dest]로 사용할 수 있도록 치환해 줍니다. define은 선행처리기로 '=' 이나 ';'를 사용하지 않습니다. define은 프로그래머가 편리하게 작업을 할 수 있도록 해주며, 일반적으로 아래와 같은 용도로 사용합니다.
게임에서 아래와 같이 for 루프를 돌면서 10명의 적을 처리하는 루틴이 있다고 가정합니다. 소스의 여러곳에 아래와 같이 적의 합인 10이란 숫자가 들어 가게 될 것 입니다.
여기서 10은 흔히 매직넘버라고 불리우는 용도가 불분면한 상수로, 숫자로 되어 있기 때문에 소스를 완전히 이해하고 있지 않으면 정확한 의미를 알기 힘듭니다. 또한 적의 숫자에 변경이 있을 경우에는 소스 곳곳의 적의 수 10을 변경된 숫자로 수정하여야 합니다.
만약 적의 수를 define해서 사용하면 의미가 명확해지며, 숫자가 변경되어도 위와 같이 적의 숫자가 사용된 소스의 모든 곳을 변경할 필요 없이 define되어 있는 곳만 변경하면 됩니다.
가능하면 숫자나 문자열을 직접 사용하는 것 보다는, define, 배열 또는 개발 툴에서 제공하는 방법을 이용하여 상수/변수화 또는 모듈화 시키는 것이 소스를 유지보수하기에 좋습니다.
아래와 같이 소프트웨어 명을 define으로 선언 해 놓으면, 만약 소프트웨어 명이 변경되더라도 소스에서 한 곳만 변경하면 소프트웨어명을 출력하는 모든 곳이 변경됩니다.
#define APP_NAME "Cocoa"
define은 ()로 인자를 넘길 수 있기 때문에, 함수와 비슷한 간단한 매크로를 작성하여 편리하게 사용할 수 있습니다. 아래는 매크로로 사용한 몇가지 예입니다.
#define ABS(a) (((a)>=0)?(a):(-(a)))
절대값을 반환합니다. ()가 많이 쓰인 이유는 a에 연산자가 포함되어 있을 경우에 연산자 우선 순위에 의해 원치 않는 결과를 방지하기 위해서 입니다.
#define NOT_USED(a) (a = a)
컴파일러는 일반적인 경고 옵션에서 사용하지 않는 변수에 대해 경고를 내 보냅니다. 만약 잠시 사용을 하지 않을 때, not used 경고를 방지하기 위한 매크로 입니다. 이는
int a;
a = a;
로 경고를 방지 하는 것 보다
int a;
NOT_USED(a);
로 사용하는 것이 의미가 명확합니다.
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
a, b를 비교 하여 더 큰 수 또는 작은 수를 반환합니다.
아래와 같이 연산자나 제어문을 변경해서 사용할 수 있습니다. 용도는 명확해 질 수 있지만, C 예약어들이기 때문에 다른 프로그래머가 소스를 볼 경우에 혼돈이 있을 수 있습니다. 필요한 곳에 적절하게 사용하면 소스에 대한 이해를 도와 주고, 변경을 용이 하게 할 수 있습니다.
MS 윈도우 프로그래밍 환경에서 win.h란 헤더파일을 보시면 define의 적극적인(?) 사용법이 많이 나와있으니, 참조해 보시기 바랍니다.
define은 ifdef, ifndef, else, endif등과 함께 컴파일 시 해당 내용을 포함 또는 미포함되도록 하여, 효율적인 프로그래밍을 할 수 있도록 해 줍니다. 이의 예는 헤더 파일(*.h)에서 가장 흔하고 쉽게 찾아 볼 수 있습니다.
여러 소스파일에서 같은 변수, define등 이 선언된 헤더파일을 중복해서 include할 경우에는 중복선언의 오류가 발생합니다. 이를 방지하기 위해 일반적으로 헤더파일의 처음과 끝을 아래와 같이 처리 합니다.
위와 같은 소스로 컴파일러는 여러 소스파일에서 헤더파일이 여러번 include 되더라도 _MY_H가 define 되기 전인 첫번째 사용된 include에서만 헤더파일을 포함하고, 이 후는 _MY_H가 define 되어 다시 MAX_MAN이나 g_curman을 선언하지 않기 때문에 오류나 경고를 막을 수 있습니다.
11.2 define을 이용한 디버깅
보통 C 컴파일러 자체에 디버깅 가능 또는 불가능 모드(릴리즈 모드)로 컴파일을 할 수 있는 옵션이 있습니다. 디버깅 모드는 디버그에 편리한 코드와 데이터들이 같이 컴파일 되어 실행파일에 포함되기 때문에, 릴리즈 모드로 컴파일 된 실행파일 보다 일반적으로 크기가 크고 실행속도가 느립니다.
그렇기 때문에 개발시에는 편리를 위해 디버깅 모드로 컴파일을 하며 코딩을 하고, 배포시에는 릴리즈 모드로 배포를 합니다. 이런 기능과 디버거등의 툴 들과는 별도로 사용자가 아래와 같은 디버깅을 위한 코드를 사용하면 쉽게 실행 상태나 오류를 찾아낼 수 있습니다.
# define ASSERT(e) assert(e)
assert는 인자의 값이 참(1)일 경우에는 동작 없이 그냥 수행 되지만, 거짓(0)일 경우에는 메시지를 출력하고 프로그램을 종료합니다.
ASSERT(i < 10);
위는 i 값이 10보다 같거나 클경우 종료됩니다. 위의 소스에서 10을 다른 작은 수로 변경하면, ASSERT내의 값이 거짓일 경우에 종료됩니다. assert는 중요한 변수 반드시 어떤 값이나 범위를 유지해야 할 경우 사용하면, 예기치 않는 변수의 값의 변동 시에 나타나는 오류를 미리 알려 주고 방지할 수 있습니다.
void Trace(char* format, ...)
대부분 C 개발툴들이 같이 사용할 수 있는 디버거 툴을 제공하고, 이를 사용하여 변수, 메모리의 값들과 상태를 확인할 수 있습니다.
이와는 별도로 프로그램 실행시에 처리결과를 실시간으로 빠르게 보고 확인해야 할 경우가 있습니다. 이를 위해 Trace란 함수를 환경과 취향에 맞게 사용하면 편리합니다. GUI 개발툴에서는 편리한 Trace 툴을 제공하는 것도 있으니, 사용하시는 개발툴을 확인해 보시기 바랍니다.
Trace 함수의 출력 부분을 파일로 변경하면, 어플리케이션의 LOG로도 사용이 가능합니다. 이는 특히 서버 프로그램의 현재 상태를 검사하거나, 지난 오류를 찾는데 유용합니다.
11.1 define
define은 컴파일 직전에 특정 문자를 지정한 문자로 대체해 주는 전처리기 입니다. C의 전처리기에 대해서는 이전 포스트에서 살펴 보았습니다. define은 아래와 같이 선언하고 사용합니다.
#define [dest] [src]
define은 [src]를 소스내에서 [dest]로 사용할 수 있도록 치환해 줍니다. define은 선행처리기로 '=' 이나 ';'를 사용하지 않습니다. define은 프로그래머가 편리하게 작업을 할 수 있도록 해주며, 일반적으로 아래와 같은 용도로 사용합니다.
1. 상수의 용도를 명확하게 하고, 변경을 용이하게 합니다.
게임에서 아래와 같이 for 루프를 돌면서 10명의 적을 처리하는 루틴이 있다고 가정합니다. 소스의 여러곳에 아래와 같이 적의 합인 10이란 숫자가 들어 가게 될 것 입니다.
for(i = 0; i < 10; i++)
{
/* 처리 */
}
{
/* 처리 */
}
여기서 10은 흔히 매직넘버라고 불리우는 용도가 불분면한 상수로, 숫자로 되어 있기 때문에 소스를 완전히 이해하고 있지 않으면 정확한 의미를 알기 힘듭니다. 또한 적의 숫자에 변경이 있을 경우에는 소스 곳곳의 적의 수 10을 변경된 숫자로 수정하여야 합니다.
만약 적의 수를 define해서 사용하면 의미가 명확해지며, 숫자가 변경되어도 위와 같이 적의 숫자가 사용된 소스의 모든 곳을 변경할 필요 없이 define되어 있는 곳만 변경하면 됩니다.
#define TOTAL_ENEMY 10
for(i = 0; i < TOTAL_ENEMY; i++)
{
/* 처리 */
}
for(i = 0; i < TOTAL_ENEMY; i++)
{
/* 처리 */
}
가능하면 숫자나 문자열을 직접 사용하는 것 보다는, define, 배열 또는 개발 툴에서 제공하는 방법을 이용하여 상수/변수화 또는 모듈화 시키는 것이 소스를 유지보수하기에 좋습니다.
아래와 같이 소프트웨어 명을 define으로 선언 해 놓으면, 만약 소프트웨어 명이 변경되더라도 소스에서 한 곳만 변경하면 소프트웨어명을 출력하는 모든 곳이 변경됩니다.
#define APP_NAME "Cocoa"
2. 간단한 매크로를 만듭니다.
define은 ()로 인자를 넘길 수 있기 때문에, 함수와 비슷한 간단한 매크로를 작성하여 편리하게 사용할 수 있습니다. 아래는 매크로로 사용한 몇가지 예입니다.
#define ABS(a) (((a)>=0)?(a):(-(a)))
절대값을 반환합니다. ()가 많이 쓰인 이유는 a에 연산자가 포함되어 있을 경우에 연산자 우선 순위에 의해 원치 않는 결과를 방지하기 위해서 입니다.
#define NOT_USED(a) (a = a)
컴파일러는 일반적인 경고 옵션에서 사용하지 않는 변수에 대해 경고를 내 보냅니다. 만약 잠시 사용을 하지 않을 때, not used 경고를 방지하기 위한 매크로 입니다. 이는
int a;
a = a;
로 경고를 방지 하는 것 보다
int a;
NOT_USED(a);
로 사용하는 것이 의미가 명확합니다.
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
a, b를 비교 하여 더 큰 수 또는 작은 수를 반환합니다.
아래와 같이 연산자나 제어문을 변경해서 사용할 수 있습니다. 용도는 명확해 질 수 있지만, C 예약어들이기 때문에 다른 프로그래머가 소스를 볼 경우에 혼돈이 있을 수 있습니다. 필요한 곳에 적절하게 사용하면 소스에 대한 이해를 도와 주고, 변경을 용이 하게 할 수 있습니다.
#define FOREVER for(;;)
#define AND &&
#define OR ||
#define EQUAL(a,b) ((a)==(b))
#define NEQUAL(a,b) ((a)!=(b))
#define INC(a) (a++)
#define DEC(a) (a--)
#define AND &&
#define OR ||
#define EQUAL(a,b) ((a)==(b))
#define NEQUAL(a,b) ((a)!=(b))
#define INC(a) (a++)
#define DEC(a) (a--)
MS 윈도우 프로그래밍 환경에서 win.h란 헤더파일을 보시면 define의 적극적인(?) 사용법이 많이 나와있으니, 참조해 보시기 바랍니다.
3. 헤더파일 사용시 중복 오류/경고를 방지합니다.
define은 ifdef, ifndef, else, endif등과 함께 컴파일 시 해당 내용을 포함 또는 미포함되도록 하여, 효율적인 프로그래밍을 할 수 있도록 해 줍니다. 이의 예는 헤더 파일(*.h)에서 가장 흔하고 쉽게 찾아 볼 수 있습니다.
여러 소스파일에서 같은 변수, define등 이 선언된 헤더파일을 중복해서 include할 경우에는 중복선언의 오류가 발생합니다. 이를 방지하기 위해 일반적으로 헤더파일의 처음과 끝을 아래와 같이 처리 합니다.
#ifndef _MY_H /* _MY_H가 define 되지 않았을 경우에만, endif까지 유효합니다. */
#define _MY_H /* _MY_H를 define 합니다. */
#define MAX_MAN 10
int g_curman;
#endif /* _MY_H */
#define _MY_H /* _MY_H를 define 합니다. */
#define MAX_MAN 10
int g_curman;
#endif /* _MY_H */
위와 같은 소스로 컴파일러는 여러 소스파일에서 헤더파일이 여러번 include 되더라도 _MY_H가 define 되기 전인 첫번째 사용된 include에서만 헤더파일을 포함하고, 이 후는 _MY_H가 define 되어 다시 MAX_MAN이나 g_curman을 선언하지 않기 때문에 오류나 경고를 막을 수 있습니다.
11.2 define을 이용한 디버깅
보통 C 컴파일러 자체에 디버깅 가능 또는 불가능 모드(릴리즈 모드)로 컴파일을 할 수 있는 옵션이 있습니다. 디버깅 모드는 디버그에 편리한 코드와 데이터들이 같이 컴파일 되어 실행파일에 포함되기 때문에, 릴리즈 모드로 컴파일 된 실행파일 보다 일반적으로 크기가 크고 실행속도가 느립니다.
그렇기 때문에 개발시에는 편리를 위해 디버깅 모드로 컴파일을 하며 코딩을 하고, 배포시에는 릴리즈 모드로 배포를 합니다. 이런 기능과 디버거등의 툴 들과는 별도로 사용자가 아래와 같은 디버깅을 위한 코드를 사용하면 쉽게 실행 상태나 오류를 찾아낼 수 있습니다.
#include <stdio.h>
#include <stdarg.h>
/* _DEBUG가 필요 없을 경우에는 주석 처리 합니다. */
#define _DEBUG
/* _DEBUG가 define 되어 있을 경우, ASSERT와 TRACE를 관련 함수로 define하고, 안되어 있을 경우에는 무효화 합니다.
*/
#ifdef _DEBUG
# include <assert.h>
# define ASSERT(e) assert(e)
# define TRACE Trace
#else
# define ASSERT(e)
inline void NO_TRACE(char* p, ...) {}
# define TRACE NO_TRACE
#endif // _DEBUG
void Trace(char* format, ...)
{
static unsigned int s_cur = 0;
va_list list;
va_start(list, format);
printf("@ %04d> ", s_cur);
vprintf(format, list);
printf("\n");
va_end(list);
fflush(stdout);
s_cur++;
}
int main()
{
int i;
for(i = 0; i < 10; i++)
{
TRACE("%d = %d", i, i);
ASSERT(i < 10);
/* 필요한 작업 */
}
}
#include <stdarg.h>
/* _DEBUG가 필요 없을 경우에는 주석 처리 합니다. */
#define _DEBUG
/* _DEBUG가 define 되어 있을 경우, ASSERT와 TRACE를 관련 함수로 define하고, 안되어 있을 경우에는 무효화 합니다.
*/
#ifdef _DEBUG
# include <assert.h>
# define ASSERT(e) assert(e)
# define TRACE Trace
#else
# define ASSERT(e)
inline void NO_TRACE(char* p, ...) {}
# define TRACE NO_TRACE
#endif // _DEBUG
void Trace(char* format, ...)
{
static unsigned int s_cur = 0;
va_list list;
va_start(list, format);
printf("@ %04d> ", s_cur);
vprintf(format, list);
printf("\n");
va_end(list);
fflush(stdout);
s_cur++;
}
int main()
{
int i;
for(i = 0; i < 10; i++)
{
TRACE("%d = %d", i, i);
ASSERT(i < 10);
/* 필요한 작업 */
}
}
# define ASSERT(e) assert(e)
assert는 인자의 값이 참(1)일 경우에는 동작 없이 그냥 수행 되지만, 거짓(0)일 경우에는 메시지를 출력하고 프로그램을 종료합니다.
ASSERT(i < 10);
위는 i 값이 10보다 같거나 클경우 종료됩니다. 위의 소스에서 10을 다른 작은 수로 변경하면, ASSERT내의 값이 거짓일 경우에 종료됩니다. assert는 중요한 변수 반드시 어떤 값이나 범위를 유지해야 할 경우 사용하면, 예기치 않는 변수의 값의 변동 시에 나타나는 오류를 미리 알려 주고 방지할 수 있습니다.
void Trace(char* format, ...)
대부분 C 개발툴들이 같이 사용할 수 있는 디버거 툴을 제공하고, 이를 사용하여 변수, 메모리의 값들과 상태를 확인할 수 있습니다.
이와는 별도로 프로그램 실행시에 처리결과를 실시간으로 빠르게 보고 확인해야 할 경우가 있습니다. 이를 위해 Trace란 함수를 환경과 취향에 맞게 사용하면 편리합니다. GUI 개발툴에서는 편리한 Trace 툴을 제공하는 것도 있으니, 사용하시는 개발툴을 확인해 보시기 바랍니다.
Trace 함수의 출력 부분을 파일로 변경하면, 어플리케이션의 LOG로도 사용이 가능합니다. 이는 특히 서버 프로그램의 현재 상태를 검사하거나, 지난 오류를 찾는데 유용합니다.
이상으로 C언어 기초 배우기를 마무리 할려고 합니다. 갑작스레 시작하여 두서도 없고, 내용이 많이 부실했던 것 같습니다. 오류와 오타가 있는 부분은 지적과 조언 부탁 드리겠습니다. 나중에 시간이 나면 정리도 하고 C언어 활용하기로 못다한 많은 얘기들을 해볼려고 합니다.
그동안 외도(?)를 많이 하였는데, 앞으로 당분간은 이 블로그의 본연의 목적인 cocoa 프로그래밍에 주력해 볼려고 합니다.
'프로그래밍 강좌 > C 언어 기초' 카테고리의 다른 글
| 10. struct, union, enum, typedef (2) | 2007.06.21 |
|---|---|
| 9. 배열 (array) (0) | 2007.06.17 |
| 8. 포인터 (pointer) (4) | 2007.06.16 |
| 7. C 함수 (function) (4) | 2007.06.15 |
| 6. 제어문 (0) | 2007.06.14 |